
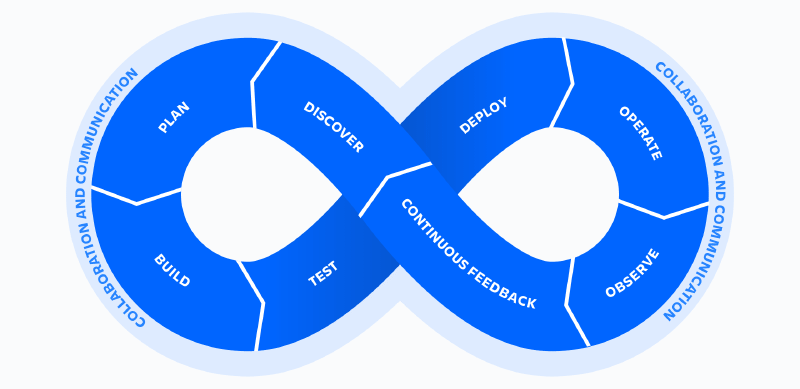
The Continuous Loop: Moving Beyond Traditional SDLC#
The diagram above represents the “Infinity Loop” of DevOps. Unlike traditional SDLC models that have a clear start and finish, DevOps is a continuous journey.
As a DevOps Engineer, my role is to ensure that the seam between the left side (Development) and the right side (Operations) is invisible. Here is how these phases translate into real-world action:
- Plan & Discover: Transforming business requirements into a technical roadmap (using Jira/Confluence).
- Build & Test: Automating code compilation and running unit tests via CI/CD pipelines (Jenkins/GitHub Actions).
- Deploy: Moving code to production environments—often using Kubernetes for orchestration.
- Operate & Observe: Monitoring system health and performance (Prometheus/Grafana) to ensure 99.9% uptime.
- Continuous Feedback: Using data from the “Observe” phase to inform the next “Plan” phase.
What is DevOps?#
DevOps is the practice of bringing Development and Operations teams together. Instead of working in separate groups, both teams share ownership of building, deploying, and maintaining software.
At its core, DevOps stands on three pillars:
- People — A shared culture of collaboration and accountability
- Process — Workflows that allow fast, reliable delivery
- Tools — Automation that removes manual, error-prone work
The goal is simple: ship better software, faster, with fewer failures.
A Brief History of DevOps#
The Problem: The Wall of Confusion#
Before DevOps, development and operations teams rarely talked to each other. Developers would write code and “throw it over the wall” to operations, who had to figure out how to run it in production. No one fully owned the outcome. Bugs went unnoticed. Deployments were feared.
This disconnect created slow releases, unstable systems, and a lot of blame-shifting.
The Evolution Timeline#
1. Waterfall (Pre-2000s) — The Age of Big Releases#
Waterfall was a sequential process: plan → design → build → test → deploy. Each step had to finish before the next one started.
The problem: A full release cycle could take 6–12 months. If something was wrong, you found out very late — after months of work. Risk was extremely high, and fixing mistakes was expensive.
One mistake discovered after 9 months of work = 9 months wasted.
2. Agile (2001) — Small Steps, Faster Feedback#
The Agile Manifesto introduced a new way of thinking: break work into small iterations called sprints, ship frequently, and get feedback early.
What improved: Development became faster and more flexible. Teams could respond to change instead of following a rigid plan.
What was missing: Agile focused on writing code, but ignored what happened after the code was written. Deploying and running that code in production was still a manual, painful process handled by a separate operations team.
3. DevOps (2009–Present) — Closing the Loop#
DevOps was born from the frustration that Agile solved development but left operations behind. The term gained momentum after Patrick Debois organized the first DevOpsDays conference in Ghent, Belgium in 2009.
The key idea: operations is a software problem too. Everything that was done manually — provisioning servers, deploying apps, monitoring systems — could be automated and treated with the same engineering discipline as writing code.
Core Practices That Shaped Modern DevOps#
Continuous Integration and Continuous Delivery (CI/CD)#
CI/CD is the backbone of DevOps automation.
- Continuous Integration (CI): Every code change is automatically tested the moment it is pushed. Bugs are caught immediately, not weeks later.
- Continuous Delivery (CD): Once code passes tests, it can be deployed to production automatically or with one click.
Tools: Jenkins, GitHub Actions, GitLab CI, CircleCI
Teams that practice CI/CD deploy code hundreds of times per day. Teams without it deploy a few times per year.
Infrastructure as Code (IaC)#
Instead of manually clicking through cloud consoles to create servers, IaC lets you define your entire infrastructure in code files. This means:
- Infrastructure is version-controlled (just like application code)
- Environments are reproducible and consistent
- Changes are reviewed, tested, and audited
Tools: Terraform, Pulumi, AWS CloudFormation
Containerization and Orchestration#
Containers package an application with everything it needs to run — libraries, configurations, dependencies — into a single portable unit.
- Docker made containers mainstream by simplifying how applications are built and shipped
- Kubernetes takes it further by managing hundreds or thousands of containers across multiple machines, handling scaling, self-healing, and rolling updates automatically
This combination eliminated the classic “it works on my machine” problem.
Monitoring and Observability#
You cannot fix what you cannot see. Modern DevOps teams treat observability as a first-class concern:
- Logs — Records of what happened
- Metrics — Numbers that measure system health (CPU, memory, request rate)
- Traces — Tracks a single request as it travels through multiple services
Tools: Prometheus, Grafana, Datadog, ELK Stack
The Rise of Site Reliability Engineering (SRE)#
SRE was pioneered by Google in the early 2000s as a way to apply software engineering principles to operations work. Google published their practices in the SRE Book (free to read online), which became a reference for the industry.
Key SRE concepts:
| Concept | What it means |
|---|---|
| SLO (Service Level Objective) | The reliability target your team agrees to meet (e.g., 99.9% uptime) |
| SLI (Service Level Indicator) | The actual metric you measure (e.g., error rate, latency) |
| SLA (Service Level Agreement) | The formal contract with users about reliability |
| Error Budget | The acceptable amount of downtime before you stop shipping new features |
| Toil | Manual, repetitive operational work that should be automated |
SRE and DevOps are complementary. DevOps is the culture. SRE is one way to implement that culture with clear metrics and engineering practices.
DevOps in the Cloud Era#
Cloud providers accelerated DevOps adoption by making infrastructure programmable through APIs. Today, DevOps engineers work heavily with:
- Public clouds — AWS, Google Cloud, Azure
- Managed Kubernetes — EKS, GKE, AKS
- Serverless — AWS Lambda, Google Cloud Run
- GitOps — Using Git as the single source of truth for both application and infrastructure state (tools: ArgoCD, Flux)
What DevOps Is Really About#
After years of working with these tools and practices, one truth stands out: DevOps is not about tools. It is about ownership.
When developers and operations engineers share responsibility for a system from day one — from writing code to running it in production — the quality improves. Deployments become routine. On-call alerts become rare. Teams move faster because they trust the systems they built.
The tools are just how you implement that ownership at scale.